
2024-02-09 東京大学
発表のポイント
- 国際共同研究コンソーシアムによる精神病ハイリスク群の脳構造画像を機械学習することにより、のちの精神病発症を判別する機械学習器を開発しました。
- 多施設から得られた大規模な脳画像データを適切に処理することにより、精神病発症より以前に撮られた脳画像によっても、のちの発症を判別できることが初めて確認されました。
- 実際の臨床現場で一般に必要とされるバイオマーカーとしての応用が期待されます。

機械学習器が学習した精神病発症予測に関わる脳構造特徴
発表概要
東京大学大学院総合文化研究科附属進化認知科学研究センター・小池進介准教授(東京大学国際高等研究所ニューロインテリジェンス国際研究機構(WPI-IRCN)連携研究者)、東京大学大学院医学系研究科脳神経医学専攻・笠井清登教授(東京大学国際高等研究所ニューロインテリジェンス国際研究機構(WPI-IRCN)主任研究者)らによる研究グループは、国際共同研究コンソーシアムによる2,000名を超える磁気共鳴画像(MRI)の脳構造画像データの機械学習を行い、精神病ハイリスク(CHR)群(注1)の発症群と健常対照(HC)群を70%以上の確率で判別可能な機械学習器(注2)を開発しました。
今回開発した機械学習器は、多施設から得られた脳画像を適切に結合し、思春期の複雑な脳発達変化による影響を考慮することで高い判別率を得ることができました。さらに、発症なし群と追跡不能群については「健常対照」と適切に判別できることも明らかにしました。本研究による機械学習器は、臨床現場で必要とされるバイオマーカー開発への応用だけでなく、精神病発症に関わる脳病態の解明に貢献することが期待されます。
発表内容
[研究の背景・先行研究における問題点]
近年、AIが注目されており、精神疾患の脳MRI研究にも機械学習や深層学習を活用した診断マーカーの開発が求められています。特に、臨床現場で判断が難しい精神病ハイリスク(CHR)に対して、発症を予測できるバイオマーカー開発が期待されていますが、いまだ高い精度で成功した例はありません。
その原因として、脳MRI計測機種間差と思春期の脳発達が挙げられます。機種間差とは、カメラの機種や撮影条件によって画質が大きく変わってしまうように、同じ脳を撮像してもMRI機種や撮像パラメータによって、解析結果が異なってしまうことです。機種間差は、精神疾患で見られる差より影響が大きいことがわかっており、近年盛んに行われている多施設共同研究などの大規模研究を行う際に問題となります。これまで本研究グループは、こうした機種間差を補正し、高精度の機械学習器を作成することに成功してきました(Zhu et al., Schizophr Bull 2022. doi: 10.1093/schbul/sbac030)。
また思春期では、脳構造特徴に大きな変化があることがわかってきました。そのため、ある精神疾患と健常対照を比較したときに、得られた結果が正常な思春期発達による変化か、精神疾患による影響かは判別できません。国際コンソーシアムEnhancing Neuro Imaging Genetics through Meta-Analysis for Clinical High Risk(ENIGMA CHR)の大規模データにおいて、健常対照群(HC群)とCHR群に差のある脳領域がいくつか明らかになりましたが、この差よりも年齢の影響が大きく、その影響も直線的ではなく曲線的な関係を示しており、脳領域や各疾患群によっても異なるなど、複雑な変化をしていることがわかりました(ENIGMA Clinical High Risk for Psychosis Working Group et al., JAMA Psychiatry 2021. doi: 10.1001/jamapsychiatry.2021.0638)。
そこで、本研究ではENIGMA CHRの多施設脳画像データを機械学習し、CHR群のうち、のちの精神病発症を確認したPS+群とHC群を高精度で判別することを目的としました。その際、機種間差を補正し、各脳構造特徴の発達曲線を高精度に求めて脳発達変化からの差を抽出したあと、機械学習器を作成しました。
[研究内容]
ENIGMA CHRで集積された2,194名(HC群1,029名、CHR群1,165名[うち、MRI計測後の追跡調査で精神病発症を確認したPS+群144名、発症しなかったPS-群793名、追跡不能だったUNK群228名];図1)の脳画像データについて、neuroComBat法(Fortin et al., NeuroImage 2018. doi: 10.1016/j.neuroimage.2017.11.024)を用い、機種間差を補正しました(図2a)。次にHC群データのみに一般化加法モデル(GAM;注3)を適用し、各脳構造特徴における年齢と性別の非線形効果、すなわち男女別の健常思春期脳発達を明らかにしました(図2b)。その上で、CHR群データにもこの思春期脳発達曲線を適用し、「標準からの逸脱度」を抽出しました(図2b)。この値を用いて、PS+群とHC群について、勾配ブースティング回帰木(XGBoost;注4)という機械学習手法により、機械学習器を構築しました(図2c)。
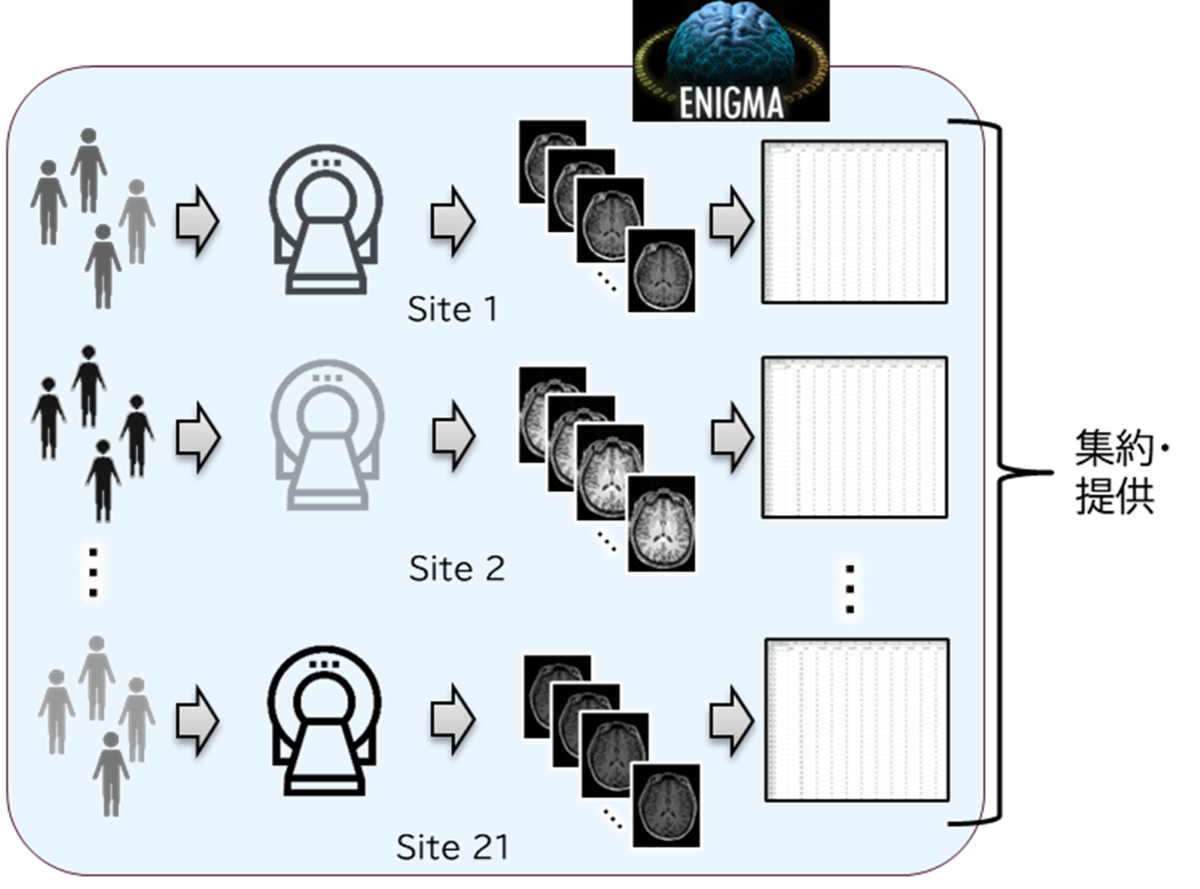
図1 ENIGMA CHRの概要
21施設で得た脳画像データを各施設で前処理し、得られた脳特徴量が提供された。
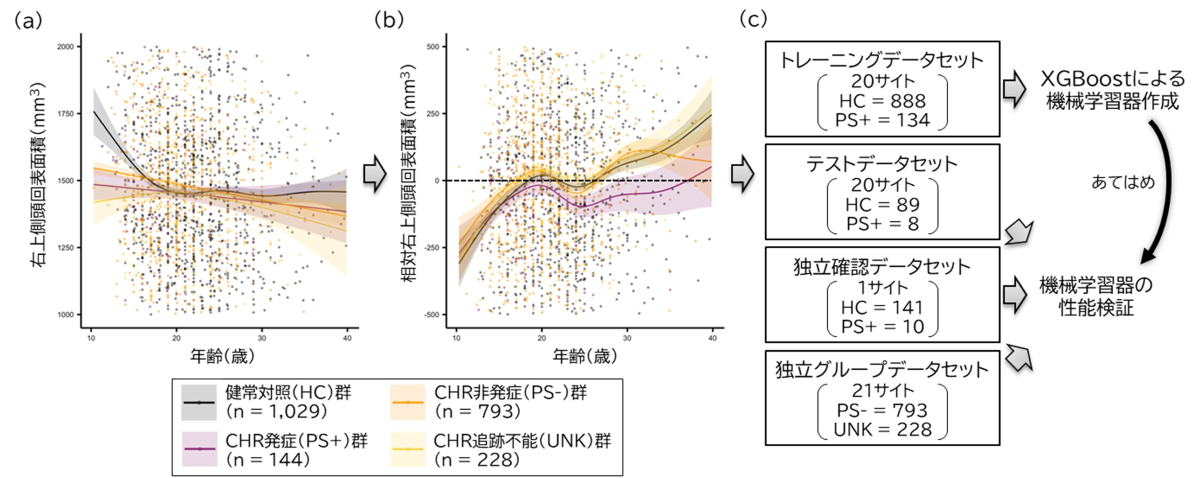
図2 機械学習器構築と、それに至るまでの変数処理
(a)機種間差補正後の右上側頭回表面積(mm3)。思春期において、群間差よりも年齢による変化が大きい。
(b)一般化加法モデル適用後の相対右上側頭回表面積(mm3)。
(c)機械学習解析の概要。トレーニングデータセットを用いて、勾配ブースティング回帰木(XGBoost)による機械学習器構築を行った。残りの3つのデータセットで、機械学習器の性能検証を行った。
その結果、機械学習器の精度はテストデータセット(注5)で85%、さらに、独立した確認データセット(注6)においても70%を超える精度を得ることが出来ました(図3a)。過去の研究と同様に、新規のデータに対しても高い精度を持つ機械学習器であることが確認されました。またPS-群およびUNK群に対しては、それぞれ73%、80%がHC群と判別され、実際の臨床に即した結果となりました(図3a)。この機械学習器では、右上前頭回、右上側頭皮質、および両側島皮質の表面積が分類に強く寄与していました(図3b)。
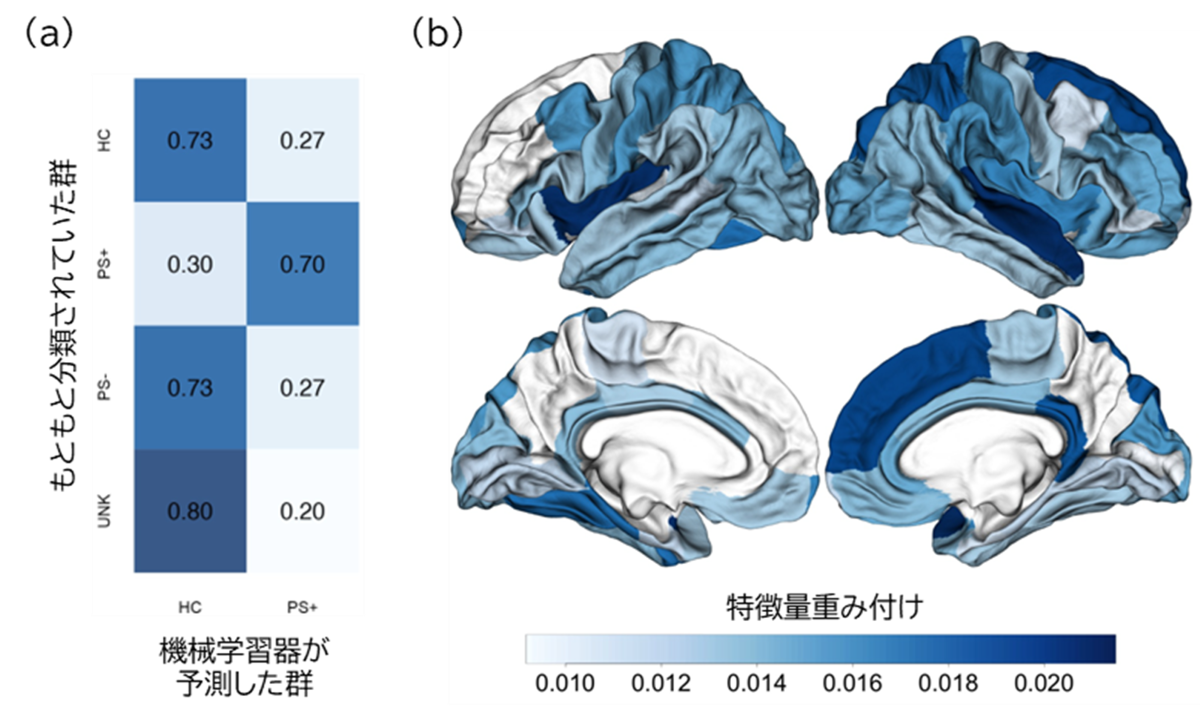
図3 得られた機械学習器の概要(a)得られた機械学習器による判別率。
(b)機械学習器が利用した特徴量をもつ脳領域。重み付けが高いほど、CHR群でみられる脳皮質表面特徴の寄与が大きい。
最後に、この機械学習器が実際の臨床現場で使用されたと想定したときに、どれくらい役立つかを検証するため、意思決定曲線分析(注7)を行いました。その結果、閾値確率がおよそ5~40%、すなわち現在行っているハイリスク群の分類を行わなければ2.5~20倍危険であると考えるのであれば、機械学習器による分類を行ったほうがよいということがわかりました(図4)。
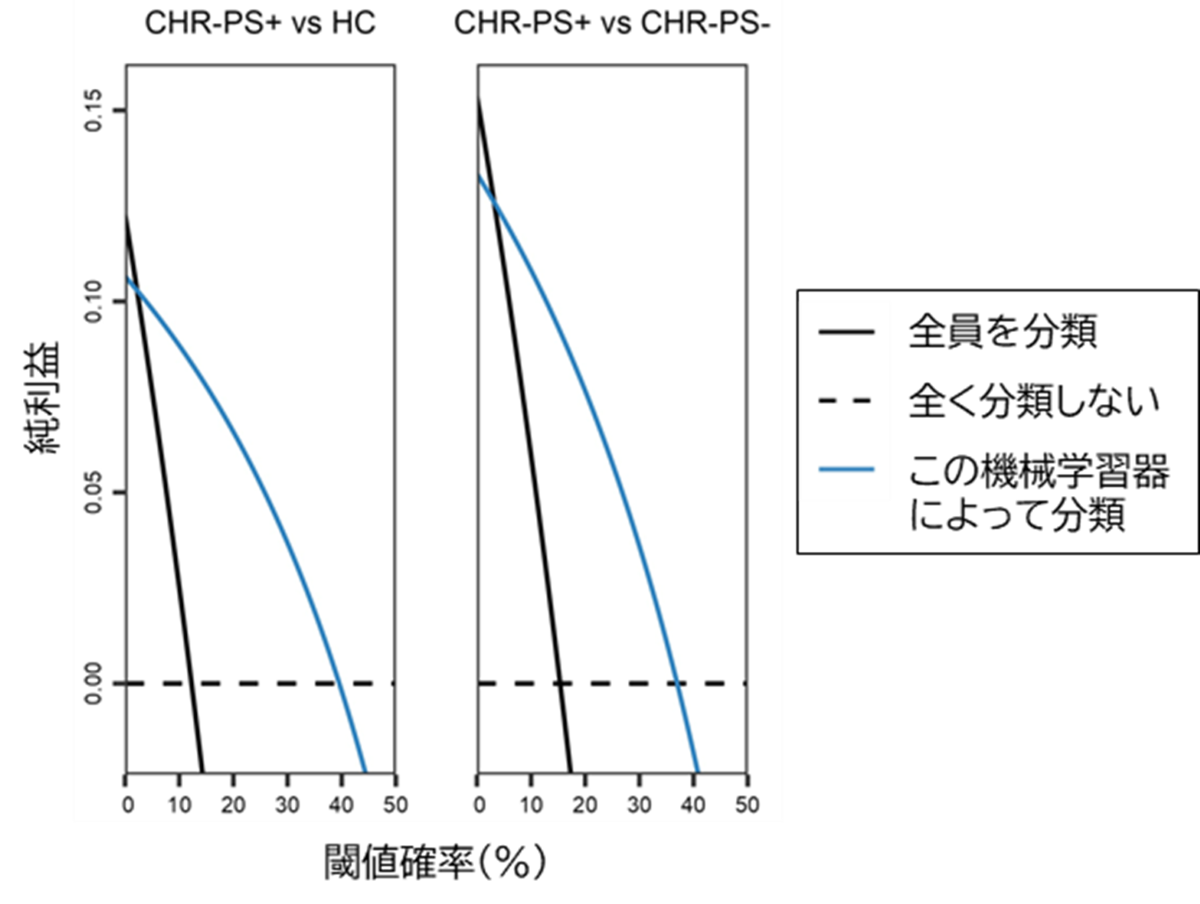
図4 意思決定曲線分析臨床現場で機械学習器使用を想定した場合、実際に分類を受けて治療や支援を開始するかどうかは、利益と不利益のバランスを考慮する必要があります。
[社会的意義・今後の予定]
これらの結果は、脳MRIに含まれる機種間差、思春期脳発達などの影響を考慮すれば、発症より以前に撮られた脳構造画像によっても、のちの発症を判別できることが初めて確認されました。また、機械学習器が学習に用いた脳領域は、過去の研究で着目された脳領域と一致しており、今後の病態解明に向けた研究にも貢献する成果と言えます。思春期の発達に応じて精神病関連の脳特徴がどのように変化するのか、また機械学習器が実際に臨床現場で役立つかどうかは、今後の新規のデータに対してさらなる検証が必要です。
発表者・研究者等情報
東京大学 大学院総合文化研究科 附属進化認知科学研究センター
小池 進介 准教授
シュ エイカン 特任助教
論文情報
雑誌:Molecular Psychiatry
題名:Using Brain Structural Neuroimaging Measures to Predict Psychosis Onset for Individuals at Clinical High-Risk
著者:Yinghan Zhu, Norihide Maikusa, Joaquim Radua, Philipp G. Sämann, Paolo Fusar-Poli, Ingrid Agartz, Ole A. Andreassen, Peter Bachman, Inmaculada Baeza, Xiaogang Chen, Sunah Choi, Cheryl M. Corcoran, Bjørn H. Ebdrup, Adriana Fortea, Ranjini RG. Garani, Birte Yding Glenthøj, Louise Birkedal Glenthøj, Shalaila S. Haas, Holly K. Hamilton, Rebecca A. Hayes, Ying He, Karsten Heekeren, Kiyoto Kasai, Naoyuki Katagiri, Minah Kim, Tina D. Kristensen, Jun Soo Kwon, Stephen M. Lawrie, Irina Lebedeva, Jimmy Lee, Rachel L. Loewy, Daniel H. Mathalon, Philip McGuire, Romina Mizrahi, Masafumi Mizuno, Paul Møller, Takahiro Nemoto, Dorte Nordholm, Maria A. Omelchenko, Jayachandra M. Raghava, Jan I. Røssberg, Wulf Rössler, Dean F. Salisbury, Daiki Sasabayashi, Lukasz Smigielski, Gisela Sugranyes, Tsutomu Takahashi, Christian K. Tamnes, Jinsong Tang, Anastasia Theodoridou, Alexander S. Tomyshev, Peter J. Uhlhaas, Tor G. Værnes, Therese AMJ. van Amelsvoort, James A. Waltz, Lars T. Westlye, Juan H. Zhou Paul M. Thompson, Dennis Hernaus, Maria Jalbrzikowski, Shinsuke Koike*, and the ENIGMA Clinical High Risk for Psychosis Working Group
DOI:10.1038/s41380-024-02426-7
研究助成
本研究は、日本医療研究開発機構(AMED)戦略的国際脳科学研究推進プログラム(国際脳)(課題番号:JP21dm0307001、JP21dm0307004)、革新的技術による脳機能ネットワークの全容解明プロジェクト(革新脳)(課題番号:JP21dm0207069)、日本学術振興会科学研究費補助金(課題番号:JP19H03579、JP20KK0193、JP21H02851、JP21H05171、JP21H05174)、科学技術振興機構ムーンショット目標2(課題番号:JPMJMS2021)、公益財団法人先進医薬研究振興財団の助成により支援されました。また、東京大学人間行動科学研究拠点(CiSHuB)、ニューロインテリジェンス国際研究機構(WPI-IRCN)の支援を受けました。
用語説明
(注1)精神病ハイリスク(CHR)群
精神病とは医学的に、幻覚や妄想などの精神病症状を呈する疾患群で、思春期における精神病の多くは統合失調症や双極性障害です。精神病ハイリスク(Clinical high risk; CHR)とは、精神病発症前の軽微な精神の不調をあらかじめとらえ、精神病の発症リスクが高い集団をより早期に支援して発症を予防しようとするために生まれた概念です。CHRは2年間でおよそ30%が精神病を発症すると言われています。一方、残り70%は発症していないため、生物学的には均一ではない集団ともいえます。CHRは、「精神病発症危険状態(At risk mental state; ARMS)」や「こころのリスク状態」とも呼ばれます。
本研究では、CHR群1,165名を対象とし、そのうちMRI計測後の2年以上の追跡調査で、精神病発症を確認した144名をPS+群、同様の追跡で発症しなかった793名をPS-群、2年以上の追跡ができなかった228名をUNK群としました。
(注2)機械学習器
機械学習器とはコンピューターが大量のデータを分析して規則性や傾向等を学習する技術システムのことです。機械学習のうち、教師あり機械学習は、すでにラベル付けされているデータを正解のラベルとともに学習させることで未知のデータを予測させる手法です。その中でも単独では精度の低い学習を繰り返して学習させることで精度を上げていく手法を教師ありアンサンブル機械学習といいます。
(注3)一般化加法モデル
一般的な統計手法の一つに、一般線形モデルというものがあります。これは、予測したい変数(y)と説明したい変数(x)の関係を線形(すなわちy = ax + b)と想定して解きます。しかし、この関係が線形ではない場合は誤った解を導いてしまいます。一般化加法モデルは、三次方程式などの線形ではない式を組み合わせ、xとyの複雑な関係を解くことができる統計モデルです。
(注4)勾配ブースティング回帰木
勾配ブースティング回帰木とは教師ありアンサンブル機械学習手法のひとつで、ブースティング(精度を向上させるために複数のモデルを順番にトレーニングすること)と決定木のひとつである回帰木を組み合わせたものです。決定木とは木を逆さまにした形のように、複数の条件に当てはめてデータを分類する手法で、その中でも回帰木は具体的な数値を推定して分類していくものです。
(注5)テストデータセット
通常、機械学習器を開発する際、データセットをトレーニングデータセットとテストデータセットに分割します。トレーニングデータセットを用いて機械学習器を開発し、テストデータセットにより機械学習器の精度を評価します。
(注6)独立確認データセット
機械学習器の開発に使われていない他施設・プロトコルのデータセットのことです。機械学習器の開発に用いたトレーニングデータセットとは異なるデータセットを用いて検証することで、より機械学習の汎用性を確認することができます。
(注7)意思決定曲線分析/閾値確率
意思決定曲線とは純利益(検査を受けることの有用性)と閾値確率の数値による曲線で、臨床において意思決定をするための指標となるものです。すべての検査や治療には、期待される利益があるとともに、検査費用や副作用などの不利益もあります。閾値確率とは、病気を見逃した場合(本研究では精神病発症を見逃した場合)、どれくらい当事者にとって不利益につながると考えているかの指標で、例えば閾値確率1%、10%であれば、その当事者がそれぞれ100倍、10倍発症を見逃すことに危険性を感じている、ということです。そのため閾値確率は、実際の病気に罹患したときの医学的な不利益だけでなく、当事者それぞれの意思決定によっても変化します。閾値確率が1%(危険度を100倍と想定)する場合、「全員を分類」が最も純利益が高いため、現在行われているハイリスク群の分類(2年で30%の発症率を予測)でも全員必ず受けて、分類結果に応じた治療や支援を受けた方が良い、ということになります。

