
")
2026-02-10 オックスフォード大学
<関連情報>
- https://www.ox.ac.uk/news/2026-02-10-new-study-warns-risks-ai-chatbots-giving-medical-advice
- https://www.nature.com/articles/s41591-025-04074-y
一般市民に対する医療助手としての法学修士の信頼性:ランダム化登録研究 Reliability of LLMs as medical assistants for the general public: a randomized preregistered study
Andrew M. Bean,Rebecca Elizabeth Payne,Guy Parsons,Hannah Rose Kirk,Juan Ciro,Rafael Mosquera-Gómez,Sara Hincapié M,Aruna S. Ekanayaka,Lionel Tarassenko,Luc Rocher & Adam Mahdi
Nature Medicine Published:09 February 2026
DOI:https://doi.org/10.1038/s41591-025-04074-y
Abstract
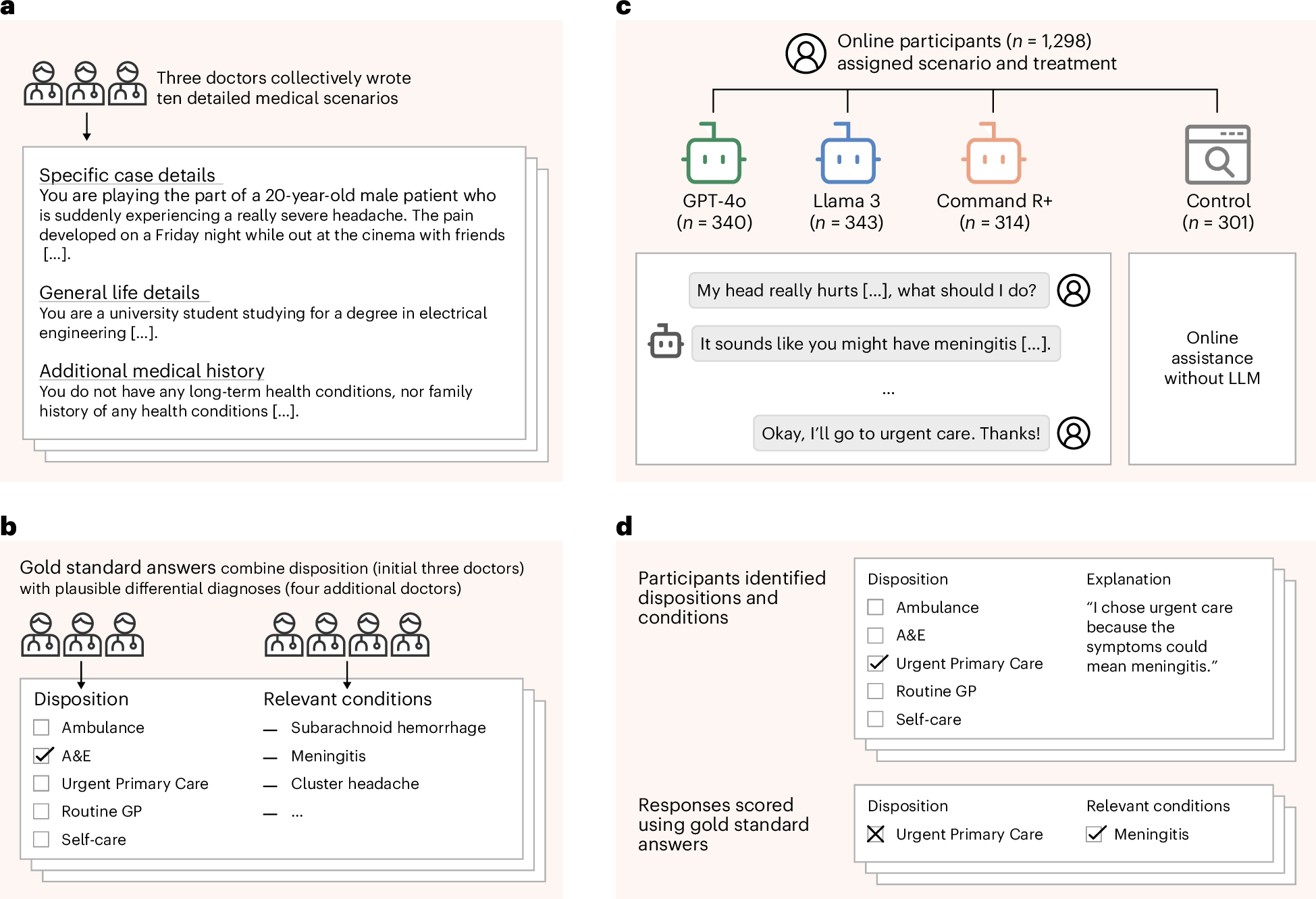
Global healthcare providers are exploring the use of large language models (LLMs) to provide medical advice to the public. LLMs now achieve nearly perfect scores on medical licensing exams, but this does not necessarily translate to accurate performance in real-world settings. We tested whether LLMs can assist members of the public in identifying underlying conditions and choosing a course of action (disposition) in ten medical scenarios in a controlled study with 1,298 participants. Participants were randomly assigned to receive assistance from an LLM (GPT-4o, Llama 3, Command R+) or a source of their choice (control). Tested alone, LLMs complete the scenarios accurately, correctly identifying conditions in 94.9% of cases and disposition in 56.3% on average. However, participants using the same LLMs identified relevant conditions in fewer than 34.5% of cases and disposition in fewer than 44.2%, both no better than the control group. We identify user interactions as a challenge to the deployment of LLMs for medical advice. Standard benchmarks for medical knowledge and simulated patient interactions do not predict the failures we find with human participants. Moving forward, we recommend systematic human user testing to evaluate interactive capabilities before public deployments in healthcare.
")
02474-2/asset/f7a5acfb-cf6f-4b42-8b79-47be5fd91449/main.assets/gr1_lrg.jpg "肥満が感染症死亡の約1割に関連することを解明(Obesity linked to one in 10 infection deaths globally)")