
2024-09-26 理化学研究所,チュービンゲン大学
理化学研究所(理研)脳神経科学センター 計算論的集団力学連携ユニットの豊川 航 ユニットリーダー、チュービンゲン大学のアレクサンドラ・ヴィット 研究員らの国際共同研究グループは、人間がいかにして異なる価値観や目的を持つ他者から学ぶことができるのかを、数理解析と行動実験から明らかにしました。
本研究成果は、価値観や目的の異なる主体で構成される複雑な社会の中で、いかにして社会的に学び合い集合知(collective intelligence)[1]を生み出すかという、社会科学における喫緊の課題の解決に貢献することが期待されます。
国際共同研究グループは、「社会的一般化(SG)学習」という、他者から得た情報と自分で獲得した情報を統合しながら試行錯誤学習する数理モデルを考案しました。この数理モデルを解析した結果、価値観の多様な集団において、模倣に基づく従来のシンプルな観察学習よりもSG学習は進化的に有利であり、かつ人々が実際に取る行動への説明力も高いことが示されました。モデルを通じた実験データ解析からは、人々が他者から得た情報を「話半分に」参考にしつつ、自分自身の学習における情報探索へうまく役立てていることが分かりました。
本研究は、科学雑誌『Proceedings of the National Academy of Sciences(PNAS)』オンライン版(9月20日付)に掲載されました。
背景
私たち人間の生活や行動の多くは、他者から学ぶことで成り立っています。他者を通じて知識を得ること、すなわち社会的学習は、人間文化の基礎でもあります。近年、不確実な環境下でいかに社会的学習を活用すべきか、また人間はそうした環境でどのように他者から学ぶのかについて、計算論的モデル[2]を用いて定量的に調べる研究が盛んに行われています。
人々が同じ問題や価値観を共有している場合、「他人の振り見て我が振り直せ」ということが有効なのは想像に難くありません。みんなが同じゴールを目指しているならば、他人のやり方をまねるのは成功への近道になり得るでしょう。これまでの研究から、人間は「いつ」「だれを」「どのように」参考にするかを調節し、意思決定の中で社会的学習をうまく活用できることが示されてきました注1)。
しかし、私たちの社会を構成する人々は、それぞれ別々のゴールや目的を持って行動しています。そうした多様な人々から成る集団では、社会的学習[3]がどのように役立つかは自明ではありません。例えば駅へ行きたいとして、適当に目についた通行人をただ追いかけても、目当ての駅へたどり着ける保証はありません。あるいは味の好みが異なる友人の薦めるレストランが、自分の味覚に合う確証はありません。これまでの社会的学習研究は、「価値観の多様性」を考慮してきませんでした。個体ごとに別々の価値関数や目的に従って行動するのは、私たち人間に限らず、他の動物でも珍しいことではありません。そこで、人間をはじめ、動物に備わっている社会的学習能力の進化やその文化進化[4]ダイナミクスを理解するためには、価値観や目的の異なる他個体からどのように学ぶかという問題に迫ることが重要です。
注1)Toyokawa W, Whalen A and Laland KN. (2019). Social learning strategies regulate the wisdom and madness of interactive crowds. Nature Human Behaviour, 3: 183-193. (doi: 10.1038/s41562-018-0518-x); Kameda T, Toyokawa W, and Tindale RS (2022) Information aggregation and collective intelligence beyond the wisdom of crowds. Nature Reviews Psychology. (doi: 10.1038/s44159-022-00054-y)
研究手法と成果
ゴールがそれぞれ違うとはいえ、他人の行動が全く参考にならないわけではありません。例えば、もしそこが町外れにある道で、他の人々が同じ方向へ歩いているとしたら、おそらくは、そちらの方向が町の中心だろうと予想がつきます。それぞれの目的地は同一でないにせよ、町へ向かうという大きな方向性では人々のゴールは一致している可能性が高いのです。つまり「他人の振り」の中には、「我が振り」の参考になる共通部分(町へ向かう)と、参考にならない部分(厳密な目的地)とが共存しているともいえます。従って、他人から得た情報のうち、自分の問題にも適用できる「一般化」された情報をいかに抽出できるかが鍵を握っていると考えられます。
そこで国際共同研究グループは、社会的学習における「一般化」を数理モデルで定式化できないかと考えました。その出発点として、個人の試行錯誤学習における一般化アルゴリズムとして確立している「ガウス過程学習」モデル[5]に着目しました。一般化は、社会的学習だけでなく個人の学習全般に通底する普遍的な問題です。例えば、あるラーメン店で大変おいしいラーメンを食べたとしましょう。するとあなたは、そのラーメンを食べた店舗のみならず、その系列店、あるいは似た種類のラーメンを出す店にまで、良い評価を与えるかもしれません。これは、まだ経験したことのない選択肢へも「一般化」して、ラーメンの価値を学習したことになります。実際に得た経験を、「概念的に似ている」選択肢にまで波及させて学習するのがガウス過程学習です(図1)。私たちは、このガウス過程学習モデルを応用し、他者から得た情報を「信頼性の低い経験」と見なして一般化できるようにしました。より「似ていない」他者からの情報にはより低い信頼性を与え、より「似ている」他者からの情報であれば、比較的高い信頼性を与えます。

図1 ガウス過程学習を使った一般化
グリッド状に並んだ白い四角形は本文中の例で用いたラーメン店などの「選択肢」を模式的に表している。四角形を一つ選択するたびに報酬がもらえる(高い値であれば良い経験、低ければ悪い経験)。近い場所にある選択肢は互いに似た値の報酬を出す。これは、同系列ラーメン店など、概念的な近さを表す。
(左図)一つの選択肢から82という報酬額がもらえた例。
(右図)ガウス過程学習の結果、選んだ選択肢だけでなく、その近傍の、「似た選択肢」の価値も変化する。
こうして考案した社会的一般化(SG)学習モデルが集団にうまく適用できるかを調べるために、自然選択シミュレーションを実施しました。プログラミング上でSG学習戦略を採用するバーチャルな個体(エージェント)を、従来提案されてきたシンプルな模倣戦略を採用する他のエージェントたちと共存させ、どの社会的学習戦略が進化的に選択されるのかを調べました。この結果、エージェントたちの似ている度合いがある程度以上高ければ(社会的相関係数が0.3以上、図2)、SG学習戦略が進化的に最も定着しやすいことが示されました。反対に、社会的相関が低すぎる設定(相関係数が0.1)では、他人の行動は全然参考にならないため、社会的情報を無視する個人の試行錯誤戦略が自然選択で有利でした(図3(1))。
次に、適応上は有利であることが分かったSG学習戦略が実際の人々の社会的学習戦略もうまく説明できるかどうかを調べるため、マルチプレイヤーのオンラインゲームを使った実験を行いました。「Prolific」注2)というクラウドソーシングサービスを介してオンライン上に集まった参加者を4人グループに分け、「惑星探索ゲーム」をプレイしてもらいました。グループに居る4人のメンバーは宇宙船のクルーという設定で、新しい惑星の鉱物資源を持ち帰るのがミッションです(図2左)。それぞれのクルーは、それぞれ別の種類の鉱物を担当し、担当の鉱物をよりたくさん獲得するのが目標です。課題への取り組みに経済的なインセンティブ(動機)を持たせるため、担当の鉱物をたくさん獲得するほど参加者が実際にもらえる金銭報酬も増やしました。
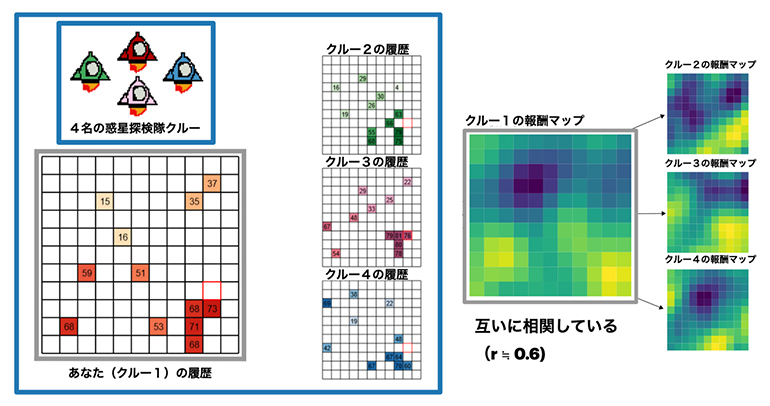
図2 惑星探索ゲームを使った社会的学習の実験課題
(左図)グリッド状に並んだ白い四角形は、地理的に相関のある「選択肢」で、一つクリックするたびに報酬がもらえる。4人の参加者が同時に参加し、互いに他のメンバーがどの選択肢を選んだか、そこからいくらの報酬を得たかが観察できる。
(右図)4人の参加者はそれぞれ別の「鉱物」をターゲットとしており、報酬地形の形は似ている(相関している)ものの、厳密には互いに異なっている。参加者には、地形マップが見えていないので、試行錯誤を通じて高い報酬の選択肢を探る必要があった。rは相関係数。
課題を実施する上で重要だったのは、各参加者が自分の探索履歴だけでなく、他のメンバーの探索履歴や獲得利得を観察することができた点です(図2左)。実は、鉱物の分布は互いに似ており、そのことは参加者へも知らされていました。つまり、誰か他のメンバーがたくさんの報酬を獲得したなら、「だいたいその近く」で自分の担当鉱物もたくさん見つかる可能性が高いだろうと一般化して推察することができます。ちなみに、参加者は他のメンバーの情報を無視することもできたし、あるいは従来の単純模倣モデルのように、他のメンバーと全く同じ行動を(一般化せずに)模倣することも可能でした。この課題を通じて、SG学習戦略が従来の模倣戦略よりも人々の行動によく当てはまるかを調べました。
実験の結果、参加者の行動を最もよく説明できたのはSG学習戦略でした。人々の行動を詳しく見てみると、他のメンバーが高い利得を得た次の試行では、まさにその選択肢を選ぶ確率よりも高い確率で、その近くにある他の選択肢を探索する傾向がありました。これは、もし参加者が他人の行動をそっくりそのまま模倣していたなら生じないパターンです。
SG学習戦略、個人の試行錯誤学習、そして2種類の単純模倣戦略のモデルを統計的なモデル比較の手法で比べた結果も一貫しており、社会的相関がある程度高い課題ではSG学習戦略が最もよく当てはまるモデルでした(図3(2))。一方、単独課題、あるいはグループ課題だが社会的相関の低い課題では、個人の試行錯誤学習のモデルが選択されました。社会的一般化が学習に役立つためには社会的相関に最低必要なレベルがあり、社会的相関がそれを下回る場合、社会的情報は無視してしまった方がよいということが示唆されます。
実験データへ当てはめたSG学習戦略モデルを詳しく分析してみると、社会的情報がない単独課題を行った場合に比べて、グループ学習の状況では「自分の知識に基づく探索」をつかさどるパラメータの値が低くなっていました。つまり、SG学習戦略を使った人々は、自分の信念に基づいた探索は控えていたといえます。その代わりに、社会的情報から示唆される場所付近を探索することで、学習に必要な探索を補っていたことが示唆されました。
SG学習戦略モデルが人々の行動をよく説明できたという結果が何を示唆するのかをまとめると次のようになります。人々は、試行錯誤しつつ意思決定を行う際、他者の行動を観察して得られた情報を「探索のツール」として用いる傾向があります。たとえ価値観や目的がふぞろいであっても、社会的情報を「こっちの方向性は悪くなさそうだ」という指針として、それを「話半分に」聞くことで、不確実な環境下における探索の効率を上げることが、進化シミュレーションおよび実験から示唆されました。同時に、自分自身で得た経験に基づいて価値を学習する際には、社会的影響を受けず、他人とは独立に学ぶ可能性も示されました。
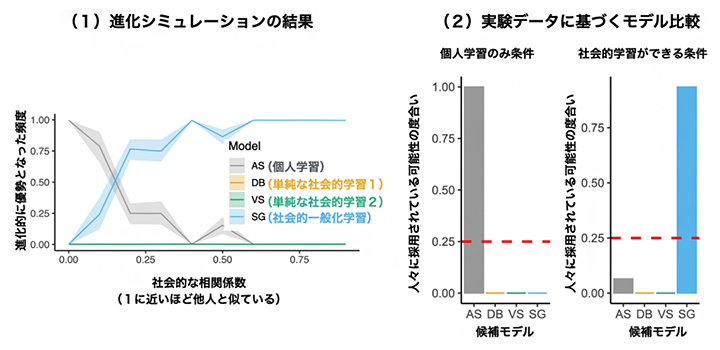
図3 進化シミュレーションと実験データ分析
(1)進化シミュレーションの結果。「どれだけ個体たちの課題が似ているか(図2右)」、つまり社会的相関を変化させながら、それぞれの相関状況においてどの学習戦略が進化するかを調べた。候補とした学習戦略モデルは、社会的学習を一切行わない「個人学習」(AS)、「社会的一般化学習」(SG)、および従来の研究で頻繁に用いられた二つの単純な模倣戦略(DB、VS)。社会的相関(相関係数)が0.2より低いときには個人学習戦略が進化した。0.2以上の社会的相関がある状況では、SG学習戦略が進化した。
(2)実験データへ上記四つのモデルを当てはめた結果、社会的情報が利用可能な場面ではSG学習戦略が人々の行動を最もよく説明できた。実験で用いた社会的相関は0.6である。
注2)Prolific
今後の期待
本研究では、機械学習アルゴリズムとしてよく使われるガウス過程モデルを社会的学習戦略のモデルへと応用した「社会的一般化学習」モデルを提案し、幅広い社会的相関の度合いに対してそれが進化的に有利な社会的学習戦略であること、そして人々の行動がSG学習戦略でよく説明できることを示しました。人々は、たとえ価値観のふぞろいな他者の行動であっても、それをうまく探索行動へ生かすことで、単独で試行錯誤する場合よりも精度の高い意思決定を行えることが計算論的モデルを通じたデータ分析から分かりました。
今後の課題は、価値観の似通う度合い(社会的相関)が人によってそれぞれ異なる場合の社会的学習です。本研究では、社会的相関は全員同一でした(例えば、全員の報酬地形がそれぞれ相関係数0.6程度で似ている状況)。しかし現実の社会では、より共通部分が多い他者もいれば、全然似ていない他者も存在します。そうした状況で、人々がより社会的相関の高い他者から選択的に情報を得るようになるのか、その結果、「エコーチャンバー」(同じ意見や見解、情報が繰り返される現象)を誘発し得る同類同士の社会的ネットワーク構造が生じてしまうのかどうかは社会科学にとって興味深くかつ重要な問題です。また、本研究のモデルでは、多様性の高さを「意思決定における目的関数(報酬地形マップ)のふぞろい度合い」で定義しましたが、別の種類の多様性、例えば行動戦略の多様性を考慮した場合に、どのような集団ダイナミクスが生じるかは、今後の課題です。
補足説明
1.集合知(collective intelligence)
ここでは、個人が単独で学習・意思決定するよりも高い精度やパフォーマンスで意思決定ができること。
2.計算論的モデル
人間の行動や意思決定パターンを説明する計算アルゴリズムを数理モデルで表したもの。機械学習や生成AIでも広く使われる強化学習モデルを人間の行動原理を説明するシンプルな模型と見なし、人間行動や人間社会の動態を定量的に研究するために使われる。
3.社会的学習
他者を観察すること、あるいは他者との接触に影響を受けて新しい知識を得ること。広く、単純に他の誰かを模倣(まね)することをはじめ、誰かから教えを受けること、ネットショップの口コミを参考にすること、あるいは本を読んで学ぶことも含まれる。
4.文化進化
行動科学、あるいは生物学領域では、社会的学習を通じて遺伝子以外の経路で伝達する情報を「文化」と定義する。文化的形質に変異があり(例えば、日本語における方言)、それが選択・継承される場合(例えば、新しく出てきた若者言葉が模倣され、その使用頻度が高まっていく)、文化形質は遺伝子的形質と同様のロジックで進化する。これを文化進化とよぶ。
5.「ガウス過程学習」モデル
過去の試行錯誤で得られた経験(例えば、xという行動からyという報酬を得た)を基に、未知の行動x’を選択したときの報酬y’を予測しながら学習と意思決定を繰り返すモデル。言い換えると、過去の経験を一般化し、未知の環境の様子を推定するモデル。
国際共同研究グループ
理化学研究所 脳神経科学研究センター 計算論的集団力学連携ユニット
ユニットリーダー 豊川 航(トヨカワ・ワタル)
チュービンゲン大学(ドイツ)Human and Machine Cognition Lab
グループリーダー チャーリー・ウー(Charley M. Wu)
研究員 アレクサンドラ・ヴィット(Alexandra Witt)
コンスタンツ大学(ドイツ)Social Psychology and Decision Sciences Group
教授 ヴォルフガング・ガイスマイヤー(Wolfgang Gaissmaier)
セントアンドリュース大学(英国)School of Biology
教授 ケヴィン・ララ(Kevin N. Lala)
研究支援
本研究は、German Federal Ministry of Education and Research (BMBF): Tübingen AI Center (FKZ: 01IS18039A)、the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation)によるGermany’s Excellence Strategy-EXC2064/1-390727645、Germany’s Excellence Strategy-EXC 2117-42203798による助成を受けて行われました。
原論文情報
Alexandra Witt, Wataru Toyokawa, Kevin N. Lala, Wolfgang Gaissmaier, Charley M. Wu, “Humans flexibly integrate social information despite interindividual differences in reward”, Proceedings of the National Academy of Sciences(PNAS), 10.1073/pnas.2404928121
発表者
理化学研究所
脳神経科学研究センター 計算論的集団力学連携ユニット
ユニットリーダー 豊川 航(トヨカワ・ワタル)
チュービンゲン大学(ドイツ)
研究員 アレクサンドラ・ヴィット(Alexandra Witt)
報道担当
理化学研究所 広報室 報道担当

