
2024-07-12 新エネルギー・産業技術総合開発機構,産業技術総合研究所
NEDOの委託事業「人と共に進化する次世代人工知能に関する技術開発事業」(以下、本事業)において、今般、国立研究開発法人産業技術総合研究所(産総研)は、画像基盤モデルを使用して少量の内視鏡画像の学習から高精度に診断する膀胱(ぼうこう)内視鏡診断支援AIを開発しました。
現在、医療分野において画像診断を支援するAIの開発が進んでいますが、医療現場で実際に画像診断支援AIが活用されている領域は限られています。特に患者数や検査数の少ない疾病や希少症例では教師データの収集が難しいため、画像診断支援AIの適用が困難でした。
今回、2種類の数式を併用して自動生成された200万枚の画像から画像基盤モデルを構築した上で、画像基盤モデルに対して従来よりも格段に少ない約9000枚の膀胱内視鏡画像を追加学習した結果、画像のみから病変の有無を診断するタスクにおいて、8名の専門医の平均を超える診断精度(感度94.3%、特異度99.4%)を実現できました。この精度は、画像認識AIの事前学習に広く使用されているデータセットであるImageNet-21kとImageNet-1kを事前学習に使った場合の診断精度を超えました。
今後、診断対象領域に合わせて画像基盤モデルを開発し、膀胱内視鏡以外にも教師データの収集が困難な医療分野への適用を進めていく予定です。
なお、この技術の詳細は、2024年7月15日から2024年7月19日まで米国オーランドで開催される 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society(EMBC2024)にて発表します。
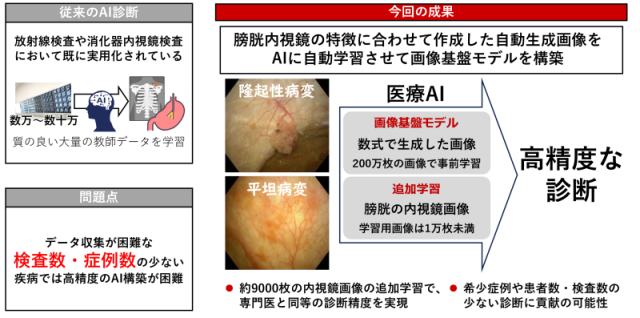
図1 画像基盤モデルを活用した膀胱内視鏡診断支援AIの構築
1.背景
現在、医療分野において内視鏡画像やエックス線写真などの画像を解析して診断を支援する画像診断支援AI※1の開発が進んでいます。このようなAIを用いた診断によって、病気の早期発見などの診断精度が向上するだけでなく、医療従事者の負担軽減の効果も期待されますが、実際の医療現場では画像診断支援AIを活用している診断領域は限られています。画像を解析するAIの開発には、教師データと呼ばれる大量の画像と付随する情報を事前に学習する必要があります。既に製品化されている画像診断支援AIには数万~数十万枚の教師データが使われていますが、患者数や検査数の少ない疾病や希少症例に関しては、この量の教師データを収集することは困難です。特に泌尿器科分野における膀胱内視鏡検査は、消化器内視鏡に比べ検査数が少なく、同じ内視鏡であっても画像診断支援AIを適用することが非常に困難でした。
こうした問題を解決するため、2020年度からNEDOの本事業※2において、産総研は、数式から自動生成した大規模画像データセットを用いてAIの画像認識モデル(学習済みモデル)を構築する手法を開発しました(2022年6月13日、2023年9月29日NEDO・産総研プレス発表※3)。この手法は事前に学習する画像と付随情報を共に数理モデルから生成するため、プライバシー保護などの倫理問題も生じず、また大量の実画像を使用せずにAIモデルを構築できます。今回、この技術を膀胱内視鏡画像診断に応用し、従来よりも格段に少ない内視鏡画像の学習でも高精度の診断を実現する画像診断支援AIを開発しました。
2.今回の成果
(1)膀胱内視鏡診断向け画像基盤モデルの開発
膀胱内視鏡画像に映る膀胱内壁の特徴を考慮し、特徴の異なる2種類の数式から自動生成した大規模画像データセットを事前学習※4する方法を考案し、膀胱内視鏡診断支援のための画像基盤モデル※5の開発に至りました。
図2に実際の膀胱内視鏡画像を示します。(A)が正常な膀胱粘膜です。膀胱がんには主に(B)隆起性病変と(C)平坦病変があります。(B)は、膀胱内壁から立体的に病変部が隆起しているため、(A)に比べ病変部の輪郭がくっきりと認識できます。一方、(C)は(A)と同じで凹凸はありませんが、粘膜表面の赤みや表面のざらつき具合など粘膜表面の質感の変化が認識できます。本事業では、この膀胱内視鏡画像における膀胱粘膜の変化に着目し、これらの特徴を認識する機能を有する画像基盤モデルを構築することを目指しました。具体的には、表面の質感の特徴を持つFractalDB※6により生成した画像100万枚と、輪郭形状の特徴を持つVisual Atoms※7により生成した画像100万枚を合わせた大規模画像データセット200万枚を用いて、画像分類AIのトップモデルであるVision Transfomer(ViT)※8を事前学習し、膀胱内視鏡画像向けの画像基盤モデルを構築しました(図3)。さらに、この画像基盤モデルに対し、病変の1259枚と、正常の7553枚、合計8812枚の膀胱内視鏡画像の追加学習※9により診断支援AIモデル(MixFDSL-2k)を構築しました。
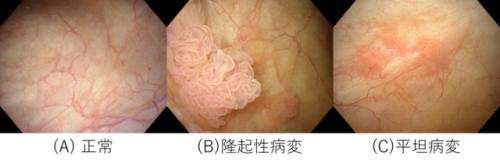
図2 膀胱内視鏡画像サンプル

図3 生成画像による画像基盤モデルの構築と膀胱内視鏡診断支援AIの学習
(2)膀胱内視鏡画像による診断性能の検証
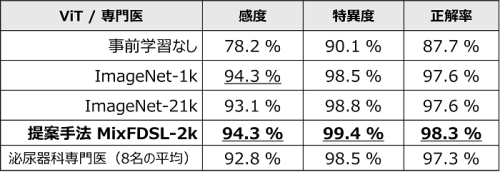
学習に用いていない膀胱内視鏡画像422枚(病変87枚、正常335枚)で検証した比較結果を表に示します。開発した診断支援AIモデル(MixFDSL-2k)は、感度94.3%、特異度99.4%、正解率98.3%を達成しました。この診断精度は、事前学習をしなかった場合(事前学習なし)と比較して感度は+16.1%、特異度は+9.3%、正解率は+10.6%向上しました。また、事前学習に広く使用されているデータセットであるImageNet-21kとImageNet-1kを事前学習に用いた場合の診断精度も超えたことを確認しました。さらに、泌尿器科勤務経験が5年以上の専門医8名に、同じ膀胱内視鏡画像422枚を1枚ずつ見せてAIと同じタスク※10を試していただいたところ、8名の平均感度、平均特異度、平均正解率のいずれも開発した診断支援AIが上回り、専門医に匹敵する結果となりました。
学習および検証に用いた膀胱内視鏡画像には、筑波大学附属病院倫理員会(No. R01-051)および産総研生命倫理委員会(No. I2019-0204)の承認を得て、筑波大学附属病院が膀胱内視鏡検査で収集した画像を用いました。画像基盤モデルの構築や診断支援AIの追加学習には、産総研が保有する、世界最大規模の人工知能処理向け計算インフラストラクチャーであるAI橋渡しクラウド「AI Bridging Cloud Infrastructure(ABCI)」を活用しています。
表 膀胱内視鏡画像に対する診断精度比較結果
3.今後の予定
汎用(はんよう)的な基盤技術として、教師データの収集が困難な他の医療領域での活用を進め、本技術の有用性を実証します。また、本技術を適用した診断支援システムを実用化し、膀胱内視鏡診断支援をはじめ、AIの活用が進んでいない医療分野でも高精度なAI診断支援を届けます。
なお同技術の詳細は、2024年7月15日から2024年7月19日まで米国オーランドで開催される46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society(EMBC2024)にて発表します。
【注釈】
- ※1 画像診断支援AI
- 医療分野において、放射線画像や内視鏡画像など、医師による検査画像の読影を補助的に支援し、見逃し・見落としを防止し、読影の作業負担の軽減や効率化を目的としているAIのことです。
- ※2 本事業
-
- 事業名:人と共に進化する次世代人工知能に関する技術開発事業
- 事業期間:2020年度~2024年度
- 事業概要:人と共に進化する次世代人工知能に関する技術開発事業
- ※3 2022年6月13日、2023年9月29日NEDO・産総研プレス発表
- ※4 事前学習
- 機械学習のコンセプトの一つで、目的のタスクのデータを学習する前に別のタスクの教師データで学習するプロセスのことです。ここでは目的である膀胱内視鏡画像を学習する前に、数式で生成した大規模画像データセットで学習させることを指します。
- ※5 画像基盤モデル
- 高い認識性能を持つ画像認識AIを開発するために、大量の画像データセットをあらかじめ学習させた事前学習済みモデルのことです。ここでは、医療画像認識のために、数式で生成した大量の画像データセットをあらかじめ学習させた事前学習済みモデルを指します。
- ※6 FractalDB
- フラクタル幾何を活用して生成された画像のデータベースのことです。画像中に部分と全体の構造が再帰的に類似するという自己相似性の特徴を有し、比較的単純な数式から複雑な画像パターンを構成可能であるという性質をもちます。
Kataoka, H., Okayasu, K., Matsumoto, A., Yamagata, E., Yamada, R., Inoue, N., Nakamura, A. and Satoh, Y., “Pre-training without natural images,” Proc. IEEE/CVF Asian Conference on Computer Vision(ACCV)(2020). - ※7 Visual Atoms
- 原子の軌道成分をパラメータ化した関数で定義した描画手順により、2種類の正弦波を合成した輪郭画像で構成された人工画像データセットのことです。
Takashima, S., Hayamizu, R., Inoue, N., Kataoka, H. and Yokota, R., “Visual atoms: Pre-training vision transformers with sinusoidal waves,” Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), 18579–18588(2023). - ※8 Vision Transformer(ViT)
- 元々は自然言語解析のために開発された、ニューラルネットワークの一種であるTransformerを、画像認識タスクに適用した手法のことです。画像認識タスクにおいて、これまで主流であったCNN(Convolutional Neural Network)モデルより優れた結果を達成している手法です。
- ※9 追加学習
- 機械学習のコンセプトの一つで、事前に学習したモデルを新しいタスクやデータに適応させるプロセスのことです。ここでは数式により生成した画像を用いて学習した画像基盤モデルを、膀胱内視鏡画像のデータを用いて再学習させることを指します。
- ※10 AIと同じタスク
- 内視鏡検査画像から切り出した静止画像422枚をランダムに表示し、その画像の情報だけから病変があるかないかを2択で回答するタスクのことです。実際の内視鏡検査では、医師は内視鏡の操作をしながら、画像に映る膀胱粘膜の様子と共に、患者のカルテ情報、問診情報、前後の膀胱内視鏡画像の情報なども含め総合的に判断して診断しています。
4.問い合わせ先
(本ニュースリリースの内容についての問い合わせ先)
NEDO AI・ロボット部 AI共進化・リモートチーム 担当:芝田、宮本
産総研 人工知能研究センター 機械学習機構研究チーム
研究チーム長 野里博和、研究員 Kim Wonjik
問い合わせ先:ブランディング・広報部 報道室
(その他NEDO事業についての一般的な問い合わせ先)
NEDO 経営企画部 広報企画・報道課

