少数医用画像に対する階層的転移学習による機械学習法
2021-03-02 理化学研究所,東北大学
理化学研究所(理研)光量子工学研究センター画像情報処理研究チームの横田秀夫チームリーダー、安光州客員研究員、秋葉正博客員研究員、東北大学大学院医学系研究科眼科学教室の中澤徹教授、面高宗子助教らの共同研究チームは、階層転移学習[1]を適用し、少数の医用画像から緑内障の病態を自動分類する機械学習[2]モデルを構築し、治療方針を決めるための有用な情報を提示することに成功しました。
本研究成果の機械学習法による画像診断システムは、緑内障に限らず、ラベル付きデータ[3]を収集することが困難な医療分野で、少数の医用画像から高精度な病態分類の機械学習モデルを開発する手法として有用です。
緑内障の診断には、視神経乳頭[4]形状に基づく分類(ニコレラ分類)が有効です。しかし、医師が眼底検査画像の読影により主観的に判断して分類するため、客観性がありませんでした。
今回、共同研究グループは、医師の診断プロセスに学んだ機械学習法を独自に開発しました。この機械学習法により、眼底検査[5]装置の光干渉断層計(OCT)[6]で撮影した画像データを用いて、緑内障病態分類モデルを構築しました。このモデルでは、階層転移学習を用いない従来法に比べて専門医による分類結果との一致度が高精度(Cohen’s Kappa[7]:0.809)であり、データ数を1/4に減らしても高精度を維持しました。
本研究は、科学雑誌『Scientific Reports』オンライン版(3月1日付)に掲載されます。

本研究で開発した機械学習法の手順
背景
近年、機械学習を医療分野に応用するための研究が盛んに行われ、さまざまな疾患のスクリーニングに利用されつつあります。しかし、機械学習を治療方針の決定に結びつけ、病態に応じた疾患細分類に適用した研究はまだ少ない状況です。一方で、機械学習の中でも深層学習では、高精度を得るために大量のラベル付きデータ(正解が既に分かっているデータ)が必要ですが、医療分野で診断に関わるラベルを大量に集めることは困難であり、いかにして少数のデータで高精度な機械学習モデルを作るかが課題となっていました。
緑内障は視神経が障害を受け、視野を失っていく眼疾患で、さまざまな危険因子により発症するため、病態の細分化や治療の個別化が望まれています。1996年にニコレラらが提唱した視神経乳頭形状に基づく分類には、緑内障病態の重要な危険因子が含まれています。視神経乳頭形状分類は、Focal Ischemia(FI)型、General Enlargement(GE)型、Myopic(MY)型、Senile Sclerosis(SS)型の四つに分けられ、型ごとに臨床的な特徴や、進行スピード、障害部位が異なります(図1)。緑内障専門医はこの分類により緑内障の病態を理解し、治療方針を決めますが、これまでは医師のカラー眼底検査などの読影による主観的判断によるため、客観性がありませんでした。
共同研究チームは、2019年に正常か緑内障かを自動診断できる機械学習モデルを開発していました注1)。今回はその研究を発展させ、医療全般に使える機械学習法を構築し、その効果を緑内障で評価することを目指しました。
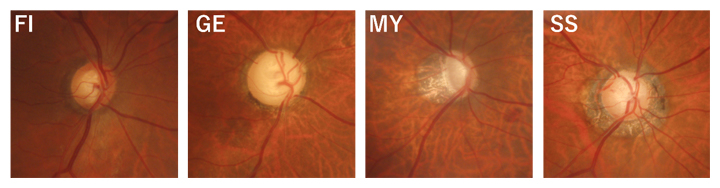
図1 視神経乳頭形状分類(ニコレラ分類)
緑内障の診断に使われる分類の眼底検査画像。FI型(神経弱い)、GE型(眼圧)、MY型(近視)、SS型(心血管障害合併)の四つに分けられる。
注1)2019年3月28日のプレスリリース「人工知能による高精度緑内障自動診断」
研究手法と成果
共同研究チームは医師の診断プロセスを模倣することにより、少数の医用画像データから疾患の病態を自動分類する機械学習法を次の手順に従って開発しました。
1)正常と疾患を区分するモデルを作成する。
2)1)で構築済みのモデルからの情報を活用した階層転移学習によって、疾患細分類モデルを作成する。
3)1)と2)で構築済みの複数のモデルからの情報に基づいて、統合的判断基準を作成する。
この機械学習法を用いて、緑内障の細分類を行う高精度な機械学習モデルの構築を試みました。
まず、緑内障専門医2名が各症例について正常と視神経乳頭形状分類のどの型に当てはまるかを判断し、分類結果が2名で一致した954眼のデータを用いました。それらの症例に対して、眼底の2次元断面を測定する光干渉断層計(OCT)で撮影した3次元ボリュームデータから、特徴が現れやすい4種類の画像を抽出して、機械学習の入力データとしました(図2)。集めたデータをランダムに二つのグループに分け、739眼は機械学習モデルの訓練に、215眼は機械学習モデルの性能検証に利用しました。
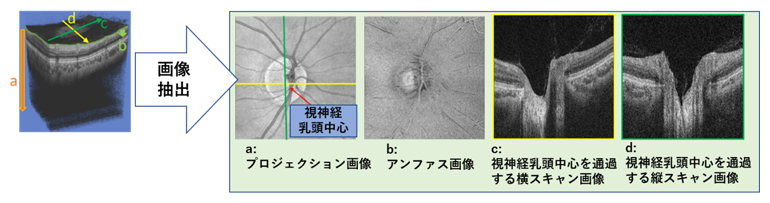
図2 機械学習の入力データ
光干渉断層計(OCT)の3次元ボリュームデータから、特徴が現れやすい4種類の画像を抽出して、機械学習の入力データとした。
次に、緑内障の細分類を行う機械学習モデルを以下の手順で作成し、性能を検証しました。
1)大量の自然画像データセット(ImageNet)で訓練済みの畳み込みニューラルネットワーク(CNN)[8]モデルの一種であるVGG16モデルを用いて、転移学習[1]により、各画像が正常か緑内障かを区分するモデルを作成しました。
2)視神経乳頭形状分類を行う各画像のVGG16モデルのパラメータは1)で生成した正常疾患区分モデルから抽出された改良パラメータを用いました(階層転移学習)。
3)最後に、各画像から得られる正常、FI型、MY型、SS型、GE型それぞれの確信度[9]情報を、サポートベクターマシン(SVM)[10]を用いたスタッキング方法[11]により結合させて、最終的分類結果を算出しました。
その結果、構築した機械学習モデルと専門医による分類結果の一致度(Cohen’s Kappa:0.809)は、階層転移学習を用いない従来方法(Cohen’s Kappa:0.727)に比べて高精度であり、訓練データ数を739個からその1/4にあたる185個まで減らした場合でも同様に高精度を維持することが分かりました(図3)。
さらに、開発した画像診断システムは、経験の浅い医師の分類結果(Cohen’s Kappa: 0.408)よりも緑内障の病態を高精度に分類できることも分かりました。
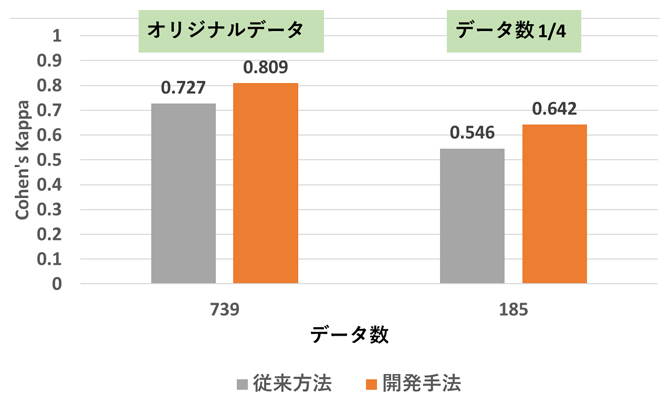
図3 機械学習モデルの精度
階層転移学習を用いない従来方法と本研究での開発手法における機械学習モデルの精度の違い。オリジナルデータ(データ数739個)の場合は開発手法のほうが高精度であり、かつデータ数をその1/4(185個)に減らしても、同様に開発手法の方が高精度だった。
今後の期待
本研究では、医師の診断プロセスを分析し、その手順を情報処理の視点から機械学習の方法に組み込むことで、独自な手法を実現しました。この機械学習法を用いた画像診断システムは、緑内障のスクリーニングだけではなく、各症例に対して病態を分類することで治療方針の決定に役立つと期待できます。
今後は、眼科撮影装置にこのシステムを取り込み、緑内障の病態を反映する視神経乳頭形状分類を客観的な画像判断によって、医師に分かりやすく提示することを計画しています。この取り組みにより、医師は緑内障の病態を判別し、患者は適切な治療を早期に受けられるようになります。現在の緑内障の治療は、進行を防げたとしても、機能の回復は困難です。そのため、診断により視野障害の進行を早期に止めることで、患者のQOL(生活の質)向上に貢献できます。
さらに、本研究で開発した手法は、緑内障に限らず、ラベル付きデータを収集することが困難な医療分野で、少数の医用画像から高精度な病態分類の機械学習モデルを開発する手法として有用な技術です。
補足説明
1.階層転移学習、転移学習
既にある領域で構築済みのモデルを他の領域で適用させる技術を転移学習という。新しいデータセットを用いて、モデルを再構築する必要がある。階層転移学習は転移学習の一種で、正常と疾患を区分(大分類)してから、大分類モデルから転移学習して細分類モデルを構築する。
2.機械学習
人間の学習能力と同様に、機械(コンピュータ)に学習能力を持たせる手法。データから機械自身が反復的に解析し、ルールを見つけ出すという特徴がある。
3.ラベル付きデータ
正解が既に分かっているデータ。
4.視神経乳頭
網膜の中枢となる部位で、全ての網膜の神経線維が視神経乳頭を通して脳へ向かう。
5.眼底検査
視覚は網膜の働きにより得られる。眼底検査とは、眼科計測装置によって、瞳孔を通して網膜を撮影し観察すること。
6.光干渉断層計(OCT)
光の干渉を用いて、非侵襲的に眼底の2次元断面を測定できる眼科装置。光ビームの2次元の走査により、3次元ボリュームの計測が可能である。OCTはOptical Coherence Tomographyの略。
7.Cohen’s Kappa
機械学習モデルの評価指標。カッパ係数とも呼ばれる。0~1の数値であり、1に近いほど高精度で、ガイドラインによると、0.8を超えたらVery Good精度、0.6~0.8であればGood精度とされる。
8.畳み込みニューラルネットワーク(CNN)
視覚野の機能からヒントを得た、ニューラルネットワークの派生版であり、主に画像分析に利用されている機械学習手法の一つである。従来の機械学習と比べて、自動的に画像から有用な特徴を抽出できる特徴抽出部がある。CNNはConvolution Neural Networkの略。
9.確信度
機械学習モデルの出力で、各分類結果をスコアリングした数値であり、0から1までの値をとる。値が1に近いほど、機械学習モデルのその分類結果に対して自信を持つことを意味する。
10.サポートベクターマシン(SVM)
「本当に分類に必要となる一部のデータ」のことをサポートベクトルと呼び、サポートベクトルを用いた機械学習法。2クラスのパターン識別器としては最も優秀な性能を持つ。SVMはSupport Vector Machineの略。
11.スタッキング方法
機械学習モデルの精度を向上させる手法の一つで、モデルを積み重ねる(Stackする)ことで精度を高める方法。
共同研究チーム
理化学研究所 光量子工学研究センター 画像情報処理研究チーム
チームリーダー 横田 秀夫(よこた ひでお)
(神戸大学大学院 システム情報学研究科 客員教授)
客員研究員 安 光州(あん こうしゅう)
(研究当時 神戸大学大学院 システム情報学研究科 博士後期課程3年、株式会社トプコン R&D本部)
客員研究員 秋葉 正博(あきば まさひろ)
(株式会社トプコン R&D本部)
東北大学 医学部 眼科学教室
教授 中澤 徹(なかざわ とおる)
助教 面高 宗子(おもだか かずこ)
本研究は、理研と東北大学、株式会社トプコンの共同研究により実施されました。
原論文情報
Guangzhou An, Masahiro Akiba, Kazuko Omodaka, Toru Nakazawa and Hideo Yokota, “Hierarchical deep learning models using transfer learning for disease detection and classification based on small number of medical images”, Scientific Reports, 10.1038/s41598-021-83503-7
発表者
理化学研究所
光量子工学研究センター 画像情報処理研究チーム
チームリーダー 横田 秀夫(よこた ひでお)
客員研究員 安 光州(あん こうしゅう)
客員研究員 秋葉 正博(あきば まさひろ)
東北大学 大学院医学系研究科 眼科学教室
教授 中澤 徹(なかざわ とおる)
報道担当
理化学研究所 広報室 報道担当
東北大学 大学院医学系研究科・医学部 広報室

