
予測・個別化医療に向けた予後に関する新たな分類を発見
2019-04-15 理化学研究所
理化学研究所(理研)科技ハブ産連本部健康医療データAI予測推論開発ユニットの川上英良ユニットリーダーらの共同研究チーム※は、血液検査データに基づく、機械学習による「卵巣がんの術前予測アルゴリズム」を開発しました。本研究成果は、予測・個別化医療に向けたがんの術前診断に貢献すると期待できます。
今回、共同研究チームは、卵巣腫瘍患者(悪性卵巣腫瘍334名、良性卵巣腫瘍101名)の年齢及び術前血液検査データ32項目に基づいて、教師あり機械学習[1]を用いることで悪性腫瘍と良性腫瘍を非常に精度良く(AUC[2]=0.968)予測する手法を開発しました。そして、同じデータに基づき、がんの進行期や組織型といった特性を予測できることも示しました。さらに、このデータ32項目に基づいて教師なし機械学習[3]を行った結果、早期がんの中に「良性腫瘍に似た血液検査データパターンを示す症例(クラスタ1)」と「進行がんに似た血液検査データパターンを示す症例(クラスタ2)」が存在していることを見いだしました。クラスタ1は再発がほとんどなかったのに対して、クラスタ2は再発率と死亡率が高いという、予後との強い関連を示しました。術前の検査データから、予後と関連する新しい疾患分類を見いだせたことで、今後の予測・個別化医療に応用できる可能性があります。
本研究は、米国の科学雑誌『Clinical Cancer Research』の掲載に先立ち、オンライン版(4月12日付け:日本時間4月12日)に掲載されました。

図 機械学習による臨床データ解析
※国際共同研究グループ
理化学研究所 科技ハブ産連本部
医科学イノベーションハブ推進プログラム
健康医療データ多層統合プラットフォーム推進グループ
健康医療データAI予測推論開発ユニット
ユニットリーダー 川上 英良(かわかみ えいりょう)
リサーチアソシエイト 石川 哲朗(いしかわ てつお)
研究パートタイマーI 古関 恵太(こせき けいた)
東京慈恵会医科大学 産婦人科学講座
教授 岡本 愛光(おかもと あいこう)
准教授 矢内原 臨(やないはら のぞむ)
助教 田畑 潤哉(たばた じゅんや)
※研究支援
本研究は、文部科学省科学研究費助成事業 基盤研究C「生命システムの破綻にひそむ秩序を解明する(研究代表者:川上英良)」、「卵巣癌の早期診断・予後予測・分子治療を目指した包括的癌関連microRNA解析(研究代表者:矢内原臨)」、公益財団法人セコム科学技術振興財団 特定領域研究助成「予防・個別医療に向けた時系列マルチモーダルデータに基づく状態遷移予測モデル構築(領域代表者:川上英良)」による支援を受けて行われました。
背景
卵巣がんは女性の生殖器腫瘍の中で最も予後が悪いものの一つで、近年卵巣がんによる死亡者数は増加しています。卵巣がんは、組織学的に少なくとも五つの型(高異型度漿液性がん、低異型度漿液性がん、類内膜がん、粘液性がん、明細胞腺がん)に分かれ、また世界産婦人科連合(FIGO)の進行期分類で、転移の有無などによって早期がん(ステージⅠ、Ⅱ)および進行がん(ステージⅢ、Ⅳ)に分かれます。
治療としては、手術による腫瘍の切除が第一選択として行われますが、化学療法への反応性も比較的良いため、手術の前後に化学療法を行うことが一般的です。化学療法への反応性は、進行期や組織型によって大きく異なるのに加え、近年PARP阻害薬[4]や抗体医薬[5]などの有効な抗がん剤が登場してきたこともあり、術前に進行期や組織型を予測し、患者ごとに適切な治療戦略を策定することが強く望まれています。
しかし従来の研究では、予後と進行期や組織型との関連は、統計的な手法によって示されてきました。こうした因子について知るためには手術や生検を行う必要があり、術前の情報のみから卵巣がんの良性・悪性や進行期、予後などの特性を予測し、治療戦略の策定に役立てることはできていませんでした。
そこで、共同研究チームは機械学習を導入することで、多項目の術前血液検査データに基づく精密な特性予測と、予後と関連するパターンの抽出を試みました。
研究手法と成果
本研究は、東京慈恵会医科大学産婦人科において2010~2017年に治療された、334名の悪性卵巣腫瘍患者と101名の良性卵巣腫瘍患者のデータを解析に用いました。共同研究チームはまず、教師あり機械学習であるランダムフォレスト法[6]を用いて、診断時の年齢および術前血液検査データ32項目のデータに基づいて、悪性腫瘍と良性腫瘍を予測しました。その結果、予測の精度の指標となるROC曲線[7]のAUCは、従来の統計的手法である多変量ロジスティック回帰[8]では0.897だったのに対し、ランダムフォレスト法では0.968に達し、非常に精度良く予測できることが分かりました(図1)。
さらに、同じ術前血液検査データに基づいて、がんの進行期(早期がんまたは進行がん)や組織型などの予測も行いました。その結果、進行期は、AUC=0.760という比較的良い精度で予測することができ(図2A)、既に知られている腫瘍マーカーに加えてCRP[9]とLDH[10]が重要であることが示され、進行期と炎症との関連が示されました(図2B)。また、組織型は、高異型度漿液性がんと粘液性がんの予測精度が比較的良く(AUC=0.785, 0.728)(図2C)、高異型度漿液性がんはCA125[11]とCA19-9[12]、粘液性がんはCEA[13]が予測のマーカーとなることが明らかになりました(図2D)。
進行期予測において、AUC=0.760とそれなりの精度は出たものの、良性・悪性の鑑別に比べて精度が良くなかったため、「早期卵巣がんと進行卵巣がんで術前血液検査のパターンが近い症例があるのではないか」という仮説をたてました。そして、サンプルの類似度を計算するために、教師なしランダムフォレスト法を用いて、教師なし機械学習を行うことにしました(図3)。
この方法を、診断時の年齢および術前血液検査データ32項目に適用し、術前の血液検査のパターンが似た人を近くに、パターンが異なる人を遠くに配置するように多次元尺度法(MDS)[14]を用いて二次元分布を描きました。すると、進行がんと良性腫瘍は明らかに異なる分布を示しましたが、早期がんは「良性腫瘍によく似た術前血液検査パターンを示す症例(クラスタ1)」と「進行がんによく似た術前血液検査パターンを示す症例(クラスタ2)」に分かれました。そして、クラスタ1では再発がほとんどなかったのに対して、クラスタ2では再発率と死亡率が高いという、予後との強い関連を示すことが分かりました(図4)。
この早期卵巣がんのクラスタは、既に知られている進行期(ステージⅠ、Ⅱ)とは異なるもので、術前血液検査データという患者の全身状態を見ることで見つかった、全く新しい分類でした。
今後の期待
本研究成果により、術前の血液検査データから高い精度で卵巣腫瘍の良性・悪性および予後と強く関連する早期卵巣がんのクラスタを予測できるようになったことで、手術前に治療方針を決めるのに役立つ情報が得られると考えられます。また、予測の際に重要な変数の組み合わせをみることで、卵巣腫瘍の進行期や組織型を特徴づける要素が明らかになりました。今後、この研究成果に基づいて、卵巣腫瘍の進行期や組織型ごとの性質を調べる基礎研究や創薬研究が進むと期待できます。
本研究でもう一つ重要なのは、単に機械学習で既知の分類を予測したことにとどまらず、今まで臨床上気づかれなかった血液検査のパターンを教師なし学習により発見した点です。機械学習は、「今までの人間の知識体系を学習する」という使い方をされることが多いのですが、本研究は「今まで臨床医も気づかなかった複雑なパターンを発見する」ことに使えることを示した先駆的な事例です。今後、機械学習は単なる予測ツールではなく、人間の知識発見と仮説形成をサポートする手段としてますます活躍していくと考えられます。
原論文情報
E. Kawakami*, J. Tabata*, N. Yanaihara, T. Ishikawa, K. Koseki, Y. Iida, M. Saito, H. Komazaki, J. S. Shapiro, C. Goto, Y. Akiyama, R. Saito, M. Saito, H. Takano, K. Yamada, and A. Okamoto, “Application of artificial intelligence for preoperative diagnostic and prognostic prediction in epithelial ovarian cancer based on blood biomarkers”, Clinical Cancer Research, 10.1158/1078-0432.CCR-18-3378
発表者
理化学研究所
医科学イノベーションハブ推進プログラム 健康医療データ多層統合プラットフォーム推進グループ 健康医療データAI予測推論開発ユニット
ユニットリーダー 川上 英良(かわかみ えいりょう)
報道担当
理化学研究所 広報室 報道担当
補足説明
-
- 教師あり機械学習
- 血液検査などの「入力データ」と良性、悪性といった既に分かっている「正解ラベル」や「正解数値」のセットに基づいて、入力データのパターンから正解を当てるための学習をコンピュータに行わせる方法。
-
- AUC
- 何らかの曲線の下の部分の面積。ROC曲線のAUCを求めることで、分類予測の精度の指標として使われることが多い。AUCはArea Under the Curveの略。
-
- 教師なし機械学習
- 正解ラベルなしで機械学習を行うことで、入力データが持つ複雑なパターンやサンプル間の類似性を発見する方法。
-
- PARP阻害薬
- DNAの相同組換え修復機構が機能していないがん細胞に、特異的に細胞死を誘導する新しい分子標的薬のこと。
-
- 抗体医薬
- 免疫反応における、抗体が抗原を認識する仕組みを利用した医薬品。抗体医薬はがん細胞などの標的のみを認識して狙い撃ちするため、薬効が高く副作用が少ないというメリットがある。
-
- ランダムフォレスト法
- ランダムサンプリングしたトレーニングデータと説明変数を用いて、数千~数万の決定木を作り、各決定木の予測結果の多数決もしくは平均を取ることで、最終結果を決定する集団学習アルゴリズム。
-
- ROC曲線
- 分類予測の性能を、判定の閾値を動かしていったときの特異度と感度の変化を二次元平面上に表した曲線。理想的な曲線は特異度、感度ともに1.0のところを通る。ROCはReceiver Operating Characteristicの略。
-
- 多変量ロジスティック回帰
- 複数の説明変数を用いて、現象の発生確率(例えば、卵巣腫瘍が悪性である確率)をモデル化する統計学的な手法。
-
- CRP
- 体内で炎症が起きたり、組織が壊れたりしたときに血液中に現れるタンパク質。通常時はほとんど検出されないため、炎症の指標とされる。CRPはC-Reactive Proteinの略。
-
- LDH
- 乳酸デヒドロゲナーゼ。ほとんどの組織に存在する可溶性タンパク質で、乳酸とピルビン酸の相互変換を触媒する。組織が傷害すると血液中に放出されるため、組織損傷の指標となる。
-
- CA125
- 卵巣漿液性のう胞腺がんの培養細胞株を用いて作製されたモノクローナル抗体が認識する高分子量の糖タンパク質。卵巣がんのマーカーとしてして使われる。
-
- CA19-9
- ヒトの膵管、胆管、前立腺、胃、大腸、子宮内膜といった腺組織に存在する糖鎖抗原で、これらの組織の異常増殖により血中に放出されるため、膵がん、胆のうがん、胆管がん、卵巣がんなどでマーカーとして使われる。
-
- CEA
- 大腸がん組織から発見された糖タンパク質で、各種消化器系がん、肺がん、腎がんなどでマーカーとして使われる。CEAはCarcinoembryonic Antigenの略。
-
- 多次元尺度法(MDS)
- サンプル同士の類似度に基づいて、似たサンプルを近くに、異なるサンプルを遠くに配置するように分布の近似的可視化を行う方法。MDSは、Multi Dimensional Scalingの略。
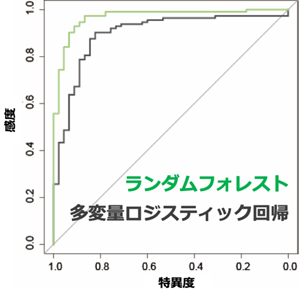
図1 悪性・良性を鑑別するROC曲線
卵巣腫瘍患者に対する悪性と良性の予測結果を示す。予測精度の指標であるROC曲線のAUCは、従来の統計的手法である多変量ロジスティック回帰では0.897だったのに対し、ランダムフォレスト法(教師あり機械学習)では0.968という非常に高い値だった。
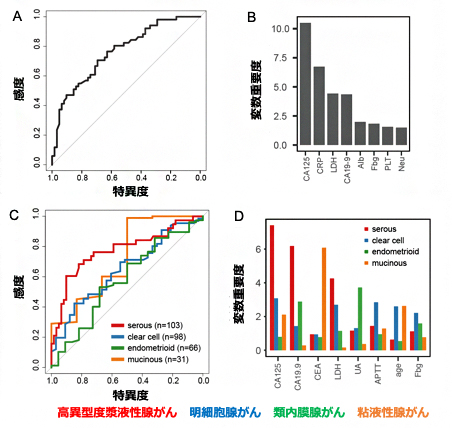
図2 卵巣がん進行期および組織型予測のROC曲線と予測に重要な変数
A:進行期が早期がんか進行がんかの予測結果。AUC=0.760の予測精度だった。
B:進行期の予測において、血液検査項目のCRPとLDHが重要であることが分かった。
C:どの組織型に属するかの予測結果。高異型度漿液性がん(赤、serous)はAUC=0.785、粘液性がん(橙、mucinous)はAUC=0.728の予測精度だった。
D:組織型の予測において、高異型度漿液性がん(赤、serous)は血液検査項目のCA125とCA19-9、粘液性がん(橙、mucinous)はCEAが重要であることが分かった。
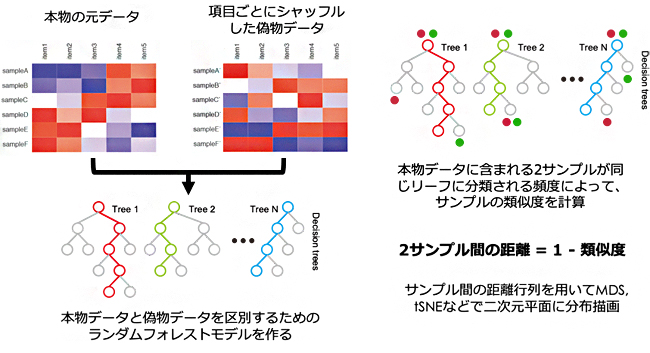
図3 教師なしランダムフォレスト法によるサンプル間距離の計算
教師なしランダムフォレストでは、元データを項目ごとにシャッフルすることで、因子のパターンをなくした偽物データを作り、本物データと偽物データを区別するためのランダムフォレストモデルを作る。このランダムフォレストモデル中で、本物データに含まれる2サンプルが同じリーフ(樹形図の末端)に分類される頻度によって、サンプルの類似度を計算する。似ているサンプルが近くに来るように、MDS(多次元尺度法)やtSNEによって二次元平面に分布描画する。
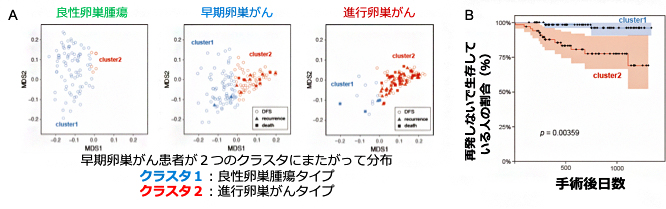
図4 教師なしランダムフォレスト法による卵巣がんクラスタリングと予後との関連
A:早期卵巣がん患者は、クラスタ1(良性腫瘍と良く似た術前血液検査パターンを示す)とクラスタ2(進行がんに良く似た術前血液検査パターンを示す)に分かれた。
B:クラスタ1とクラスタ2の無再発生存曲線。クラスタ1ではほとんど再発がなかったのに対し、クラスタ2では再発・死亡率が高かった。

