品種鑑定や新品種育成に用いるDNAマーカー開発を効率化
2019-08-06 農研機構
ポイント
カンキツのDNAマーカー1)開発支援用のデータベース「ミカンゲノムデータベース(MiGD)」を開発・公開しました。10種類のカンキツ及びその近縁野生種について、DNAマーカーの開発に必要なDNA多型情報2)を容易に探索できます。本データベースは、カンキツの有用遺伝子の特定や、新品種育成過程での優良個体の選抜、品種鑑定の効率化に役立ちます。
概要
次世代シーケンス技術の進展によりさまざまな植物でゲノム配列が解読されています。カンキツでは農研機構が2017年にウンシュウミカンの全ゲノム配列を解読し、今回新たにカラタチ3)の全ゲノム配列を解読しました。またこれまでに他の研究機関が、オレンジ、クレメンティン4)など、8種類のカンキツ及びその近縁種のゲノム配列を解読・公開しています。これらの情報をマップベースドクローニング5)等による有用遺伝子の特定や、優良個体の選抜、品種鑑定に利用するには、DNAマーカーの開発が重要となります。
農研機構は今回、カンキツのDNAマーカーの開発を支援するデータベース「ミカンゲノムデータベース(MiGD)」を開発し、ウェブ公開しました。10種類のカンキツ及びその近縁種(ウンシュウミカン、カラタチ、オレンジ、クレメンティン、ポンカン、ブンタン2種、シトロン6)およびカンキツの近縁野生種2種)について、DNAマーカー開発に必要な、種間や品種間のゲノム配列のわずかな違い(多型)を容易に探索できます。また本データベースでは、ウンシュウミカンとカラタチの全ゲノム配列情報と遺伝子のアノテーション7)情報や、カンキツ類全般で利用できる、約2,700の既存DNAマーカー情報も閲覧できます。
本データベースは、カンキツの育種事業を行う公設試等や権利侵害の輸入防止を行う税関等が、カンキツの有用遺伝子の特定や、新品種育成過程での優良個体の選抜、品種鑑定を効率的に行うのに役立ちます。
ミカンゲノムデータベース(MiGD)(英語)URL https://mikan.dna.affrc.go.jp/
関連情報
予算:運営費交付金、農林水産省委託プロジェクト「ゲノム情報を活用した農作物の次世代生産基盤技術の開発」(GMO)
問い合わせ先など
研究推進責任者 :農研機構果樹茶業研究部門 研究部門長 高梨 祐明
研究担当者 :農研機構果樹茶業研究部門 カンキツ研究領域 島田 武彦
農研機構高度解析センター 川原 善浩、伊藤 剛
静岡大学農学部 大村 三男
広報担当者 :農研機構果樹茶業研究部門 企画管理部企画連携室 広報プランナー 大﨑 秀樹
詳細情報
開発研究の背景と経緯
農研機構ではカンキツの優れた新品種の育成を効率化するため、優良形質の幼苗選抜に利用できるDNAマーカーの開発や、育成者権保護のためのDNA鑑定技術の開発を進めています。これまでDNAマーカーの開発には、クレメンティンやオレンジなど海外で多く栽培されるカンキツの全ゲノム配列情報を利用してきました。しかし、国内の優れた育種素材を最大限に活用して新品種を効率的に育成するためには、国内で広く栽培されている在来種や育種素材の全ゲノム配列を解読し、それらのゲノム配列情報やDNA多型情報などが簡単に閲覧できる操作性の優れたデータべースの開発が必要です。
カンキツでは2014年にクレメンティンやオレンジ、また、2017年にはウンシュウミカンの全ゲノム配列が解読され、公開されています(2017年2月20日付け農研機構プレスリリース「ウンシュウミカンの全ゲノムを解読 -カンキツの品種改良の効率化を期待-」)。国内の育種素材を対象とした高精度DNAマーカーの開発を加速するためには、全ゲノム配列の高精度化と操作性の優れたデータベースの開発が必要です。一方、国内でカンキツの台木として広く利用されているカラタチについては、カンキツトリステザウイルス抵抗性、疫病抵抗性、耐凍性などマンダリン類8)にはみられない優れた特性をもっていますが、全ゲノム配列は解読されておらず、有用遺伝子の単離や台木品種の育成などの取り組みは進んでいません。
研究の内容・意義
1.に公開していたウンシュウミカンの全ゲノム配列を高精度化するとともに、世界で初めてカラタチの全ゲノム配列を解読・公開しました。ゲノムサイズの大きさは、ウンシュウミカンでは3億5千万塩基対、カラタチでは2億9千万塩基対となっており、ゲノム中に41,489個と34,333個の遺伝子が存在することをそれぞれ推定しました。
2.ウンシュウミカンとカラタチの全ゲノム配列の精度は、すでに公開されているクレメンティンのものと同程度以上であり、遺伝子の構造解析やDNA多型の検出には十分な精度です。
3.ウンシュウミカンとカラタチの全ゲノム配列情報から、有用形質を支配する遺伝子の単離やDNAマーカーの開発を効率的に行えるようにするため、ゲノムアノテーションデータベース、DNA多型データベース、CAPSマーカー9)データベースを統合したミカンゲノムデータベース(MiGD)を開発しました(図1)。それぞれのデータベースは遺伝子IDで紐づけられており、利用者は本データベース内において目的とするゲノム領域の配列情報や多型情報を簡単に抽出できます。
4.ゲノムアノテーションデータベースは、キーワード検索等により任意の遺伝子のゲノム配列情報、アノテーション情報が閲覧できます。
5.DNA多型データベースには、オレンジ、ポンカン、ウンシュウミカンなど10種類のカンキツの公開ゲノム配列を比較できる形で掲載しており、目的のゲノム領域のDNA多型情報を閲覧できます。
6.CAPSマーカーデータベースには、約2,700種類のCAPSマーカーのプライマー配列情報やこれまで作成した連鎖地図10)、およびクレメンティンやウンシュウミカンの公開全ゲノム配列における位置情報などが掲載され、さらに、代表的なカンキツ品種のCAPSマーカーの遺伝子型情報、カンキツの品種識別マニュアルに利用されたプライマー情報などが閲覧できます。
7.MiGDの利用により、品種鑑定や育種選抜などに利用するDNAマーカーの開発に必要なゲノム情報を容易に取得でき(図2)、研究開発が高速化します。
8.MiGDは「https://mikan.dna.affrc.go.jp/」のサイトで公開しています。
今後の予定・期待
本成果で得られたウンシュウミカンとカラタチの全ゲノム配列から、種無し性、早生性、病害抵抗性、栽培性に関わる重要遺伝子を効率的に見出し、それらの情報を基に高精度なDNAマーカーを開発することでカンキツの新品種の育成を効率化します。また、品種開発の国際競争力の維持には、海外への不当な流出を防ぐ必要があることから、本成果の活用により、DNA鑑定技術の開発が促進され、新品種の権利保護の効率化が期待されます。
用語の解説
- 1)DNAマーカー
- ある遺伝子や染色体の領域に含まれる、またはこれらの近傍に位置する特定の塩基配列を利用した目印。葉などから取り出したDNAと適切なDNAマーカーがあれば、果実が結実するのを待たずに特定の果実形質を持つ個体を選別できます。
- 2)DNA多型情報
- ゲノムDNA中の塩基配列にみられる変異情報。
- 3)カラタチ
- カンキツの近縁野生種の一つで、国内で栽培されるカンキツ類の台木として利用されています。
- 4)クレメンティン
- ヨーロッパやアメリカで普及しているマンダリンの一種。
- 5)マップベースドクローニング
- 遺伝地図をもとに目的とする遺伝子を単離する方法。
- 6)シトロン
- インド原産のカンキツの古代種の一つで、レモンと類似しています。
- 7)アノテーション
- 解読した塩基配列に対し生物学情報、タンパク質の機能情報などを注釈付けすること。
- 8)マンダリン類
- 多様に分化したカンキツ類のうち、果実の皮が薄くてむきやすいものの総称。
- 9)CAPSマーカー
- Cleaved Amplified Polymorphic Sequenceの略。PCR増幅断片中の制限酵素サイトの変異を利用して多型を検出する方法。
- 連鎖地図
- 連鎖している遺伝子間の組換え頻度に基づいて表現型質や遺伝マーカーを配置した地図のこと。
参考図
の公開")
図1 ミカンゲノムデータベース(MiGD)を利用したワンストップで効率的なDNAマーカーの開発
MiGDは、ゲノムアノテーションデータベース、DNA多型データベース、CAPSマーカーデータベースの3種類のデータベースを統合したデータベースです。MiGDはDNAマーカー開発に必要なデータベース群から構成され、これらが遺伝子IDにより連携しているので、ワンストップで効率的にDNAマーカー開発ができます。
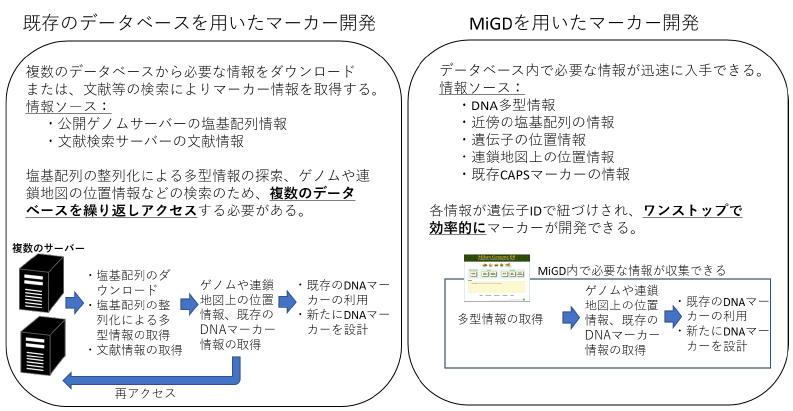
図2 DNAマーカー開発におけるミカンゲノムデータベース(MiGD)と既存のデータベースとの比較
MiGDではマーカー開発に必要なデータベースやアプリケーションソフトが搭載され、さらにデータベース内の情報が遺伝子IDで紐づけられていることから、ワンストップで効率的にDNAマーカーが開発できます。

